盘古是谁做的?
如果你是一位 NLP 从业者,你可能发现,最近的中文 NLP 社区有点热闹:「中文版 T5」、「中文版 GPT-3」以及各种大规模中文版预训练模型陆续问世,似乎要带领中文 NLP 社区跑步进入「练大模型」时代。
在此背景下,中文语言理解测评基准「CLUE」也经历了它的前辈「GLUE」所经历过的盛况:一个模型的冠军宝座还没坐热,就被一个更新的模型挤了下去。
这次刷榜的,是一个叫「盘古」的 NLP 模型。
换言之,在盘古之前,模型竞赛已经开始了,从当时的榜单图片中可以看到,参与者至少有美团、阿里、搜狗。盘古不是第一个。其实,当时GLM、CPM等也已发布,发布在悟道旗下。
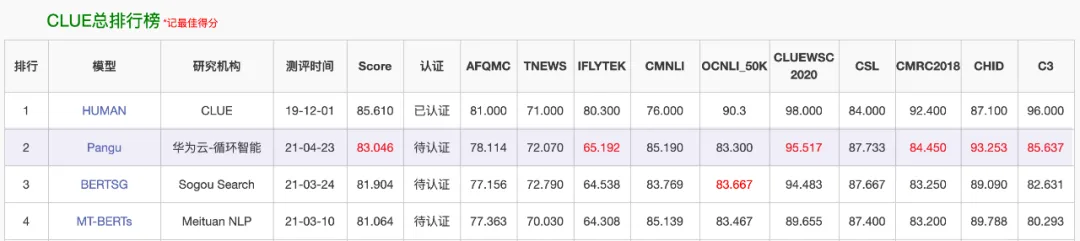
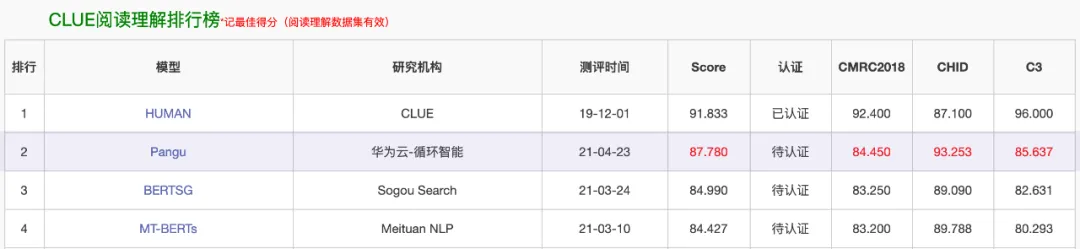
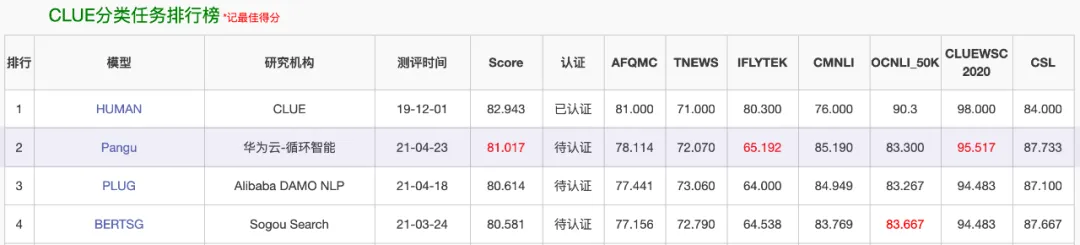
可以看到,盘古的研究机构是“华为云-循环智能”,这个“循环智能”是什么公司呢?就是杨植麟的上一家公司,也就是引发投资人提起仲裁的那家公司。
机器之心这篇文章,主体就是对杨植麟的采访。而且那个时候,Moonshot的名字就已经出现了:
在最近的一次访谈中,循环智能 NLP Moonshot 团队向机器之心介绍了这个项目的初衷、挑战和具体的解决方案。
所以,如果想尝试原盘古团队的新作,也许可以试试Kimi Moonshot的产品。
这篇文章结尾,还记录了一段预言:
清华大学计算机科学与技术系教授唐杰在前段时间接受机器之心采访时曾表示,「超大规模预训练模型的出现,很可能改变信息产业格局。继基于数据的互联网时代、基于算力的云计算时代之后,接下来可能将进入基于模型的 AI 时代。」杨植麟也同意这一观点。在他看来,这个新时代将有两大特征。
一是 AI 生产效率的变革。随着标注数据需求大幅降低,AI 生产效率将迎来两到三个数量级的提升,摆脱原来依靠大量样本的落后生产方式,进入规模化量产时代。
二是 AI 场景的指数级增加。技术的突破往往带来新市场,而目前 AI 商业化的现状就是需求很多但技术不一定满足。AI 预训练技术突破之后,马上可以解锁很多新场景,从数字化程度比较高的行业走向传统行业,从大型企业走向中小企业。
前述提到的比盘古更早发布的GLM模型,论文署名最后两位就是杨植麟和唐杰。

本作品采用知识共享署名-相同方式共享 4.0 国际许可协议进行许可。


